 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNet Super-resolution
Papers and Code
Time-aware UNet and super-resolution deep residual networks for spatial downscaling
Dec 15, 2025

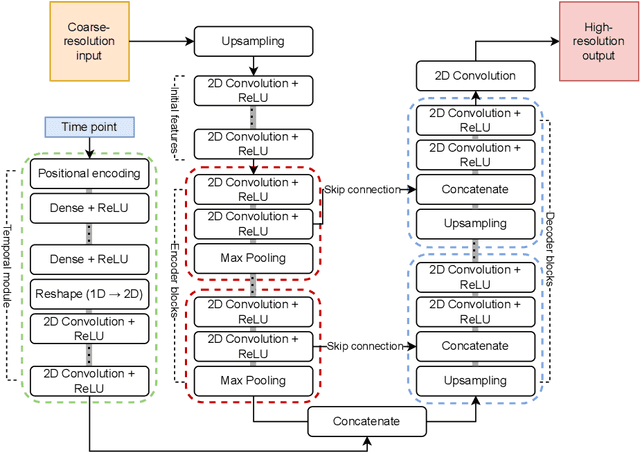
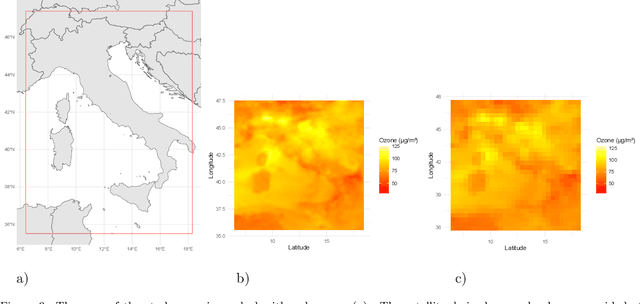
Satellite data of atmospheric pollutants are often available only at coarse spatial resolution, limiting their applicability in local-scale environmental analysis and decision-making. Spatial downscaling methods aim to transform the coarse satellite data into high-resolution fields. In this work, two widely used deep learning architectures, the super-resolution deep residual network (SRDRN) and the encoder-decoder-based UNet, are considered for spatial downscaling of tropospheric ozone. Both methods are extended with a lightweight temporal module, which encodes observation time using either sinusoidal or radial basis function (RBF) encoding, and fuses the temporal features with the spatial representations in the networks. The proposed time-aware extensions are evaluated against their baseline counterparts in a case study on ozone downscaling over Italy. The results suggest that, while only slightly increasing computational complexity, the temporal modules significantly improve downscaling performance and convergence speed.
Fine-structure Preserved Real-world Image Super-resolution via Transfer VAE Training
Jul 27, 2025Impressive results on real-world image super-resolution (Real-ISR) have been achieved by employing pre-trained stable diffusion (SD) models. However, one critical issue of such methods lies in their poor reconstruction of image fine structures, such as small characters and textures, due to the aggressive resolution reduction of the VAE (eg., 8$\times$ downsampling) in the SD model. One solution is to employ a VAE with a lower downsampling rate for diffusion; however, adapting its latent features with the pre-trained UNet while mitigating the increased computational cost poses new challenges. To address these issues, we propose a Transfer VAE Training (TVT) strategy to transfer the 8$\times$ downsampled VAE into a 4$\times$ one while adapting to the pre-trained UNet. Specifically, we first train a 4$\times$ decoder based on the output features of the original VAE encoder, then train a 4$\times$ encoder while keeping the newly trained decoder fixed. Such a TVT strategy aligns the new encoder-decoder pair with the original VAE latent space while enhancing image fine details. Additionally, we introduce a compact VAE and compute-efficient UNet by optimizing their network architectures, reducing the computational cost while capturing high-resolution fine-scale features. Experimental results demonstrate that our TVT method significantly improves fine-structure preservation, which is often compromised by other SD-based methods, while requiring fewer FLOPs than state-of-the-art one-step diffusion models. The official code can be found at https://github.com/Joyies/TVT.
Super-Resolution Optical Coherence Tomography Using Diffusion Model-Based Plug-and-Play Priors
May 20, 2025We propose an OCT super-resolution framework based on a plug-and-play diffusion model (PnP-DM) to reconstruct high-quality images from sparse measurements (OCT B-mode corneal images). Our method formulates reconstruction as an inverse problem, combining a diffusion prior with Markov chain Monte Carlo sampling for efficient posterior inference. We collect high-speed under-sampled B-mode corneal images and apply a deep learning-based up-sampling pipeline to build realistic training pairs. Evaluations on in vivo and ex vivo fish-eye corneal models show that PnP-DM outperforms conventional 2D-UNet baselines, producing sharper structures and better noise suppression. This approach advances high-fidelity OCT imaging in high-speed acquisition for clinical applications.
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
Mar 30, 2025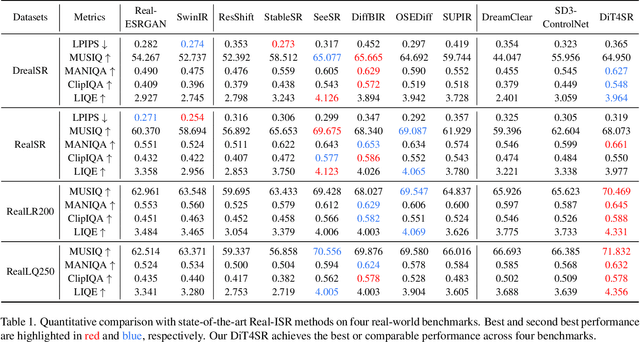
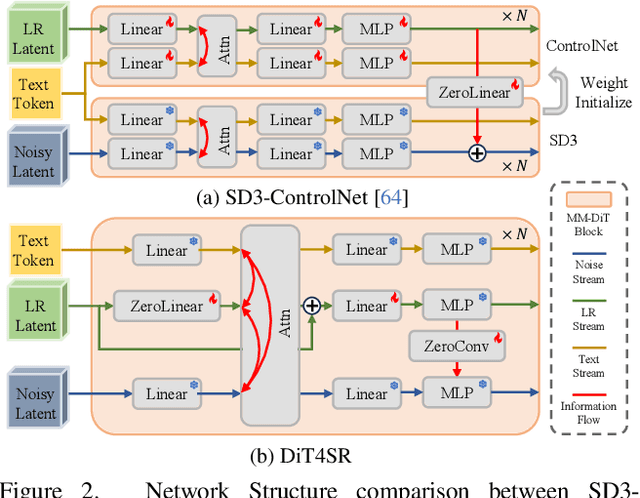
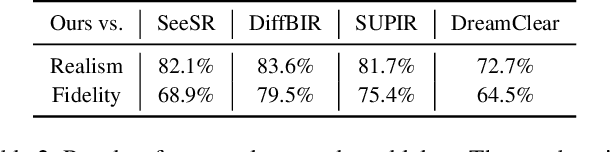
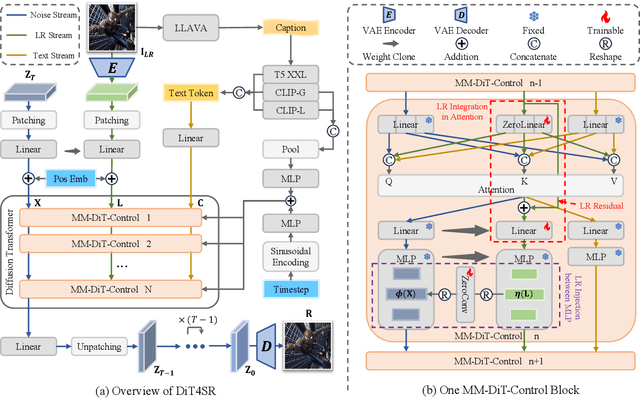
Large-scale pre-trained diffusion models are becoming increasingly popular in solving the Real-World Image Super-Resolution (Real-ISR) problem because of their rich generative priors. The recent development of diffusion transformer (DiT) has witnessed overwhelming performance over the traditional UNet-based architecture in image generation, which also raises the question: Can we adopt the advanced DiT-based diffusion model for Real-ISR? To this end, we propose our DiT4SR, one of the pioneering works to tame the large-scale DiT model for Real-ISR. Instead of directly injecting embeddings extracted from low-resolution (LR) images like ControlNet, we integrate the LR embeddings into the original attention mechanism of DiT, allowing for the bidirectional flow of information between the LR latent and the generated latent. The sufficient interaction of these two streams allows the LR stream to evolve with the diffusion process, producing progressively refined guidance that better aligns with the generated latent at each diffusion step. Additionally, the LR guidance is injected into the generated latent via a cross-stream convolution layer, compensating for DiT's limited ability to capture local information. These simple but effective designs endow the DiT model with superior performance in Real-ISR, which is demonstrated by extensive experiments. Project Page: https://adam-duan.github.io/projects/dit4sr/.
A Staged Deep Learning Approach to Spatial Refinement in 3D Temporal Atmospheric Transport
Dec 14, 2024High-resolution spatiotemporal simulations effectively capture the complexities of atmospheric plume dispersion in complex terrain. However, their high computational cost makes them impractical for applications requiring rapid responses or iterative processes, such as optimization, uncertainty quantification, or inverse modeling. To address this challenge, this work introduces the Dual-Stage Temporal Three-dimensional UNet Super-resolution (DST3D-UNet-SR) model, a highly efficient deep learning model for plume dispersion prediction. DST3D-UNet-SR is composed of two sequential modules: the temporal module (TM), which predicts the transient evolution of a plume in complex terrain from low-resolution temporal data, and the spatial refinement module (SRM), which subsequently enhances the spatial resolution of the TM predictions. We train DST3DUNet- SR using a comprehensive dataset derived from high-resolution large eddy simulations (LES) of plume transport. We propose the DST3D-UNet-SR model to significantly accelerate LES simulations of three-dimensional plume dispersion by three orders of magnitude. Additionally, the model demonstrates the ability to dynamically adapt to evolving conditions through the incorporation of new observational data, substantially improving prediction accuracy in high-concentration regions near the source. Keywords: Atmospheric sciences, Geosciences, Plume transport,3D temporal sequences, Artificial intelligence, CNN, LSTM, Autoencoder, Autoregressive model, U-Net, Super-resolution, Spatial Refinement.
Edge-SD-SR: Low Latency and Parameter Efficient On-device Super-Resolution with Stable Diffusion via Bidirectional Conditioning
Dec 09, 2024



There has been immense progress recently in the visual quality of Stable Diffusion-based Super Resolution (SD-SR). However, deploying large diffusion models on computationally restricted devices such as mobile phones remains impractical due to the large model size and high latency. This is compounded for SR as it often operates at high res (e.g. 4Kx3K). In this work, we introduce Edge-SD-SR, the first parameter efficient and low latency diffusion model for image super-resolution. Edge-SD-SR consists of ~169M parameters, including UNet, encoder and decoder, and has a complexity of only ~142 GFLOPs. To maintain a high visual quality on such low compute budget, we introduce a number of training strategies: (i) A novel conditioning mechanism on the low resolution input, coined bidirectional conditioning, which tailors the SD model for the SR task. (ii) Joint training of the UNet and encoder, while decoupling the encodings of the HR and LR images and using a dedicated schedule. (iii) Finetuning the decoder using the UNet's output to directly tailor the decoder to the latents obtained at inference time. Edge-SD-SR runs efficiently on device, e.g. it can upscale a 128x128 patch to 512x512 in 38 msec while running on a Samsung S24 DSP, and of a 512x512 to 2048x2048 (requiring 25 model evaluations) in just ~1.1 sec. Furthermore, we show that Edge-SD-SR matches or even outperforms state-of-the-art SR approaches on the most established SR benchmarks.
Self-Prior Guided Mamba-UNet Networks for Medical Image Super-Resolution
Jul 08, 2024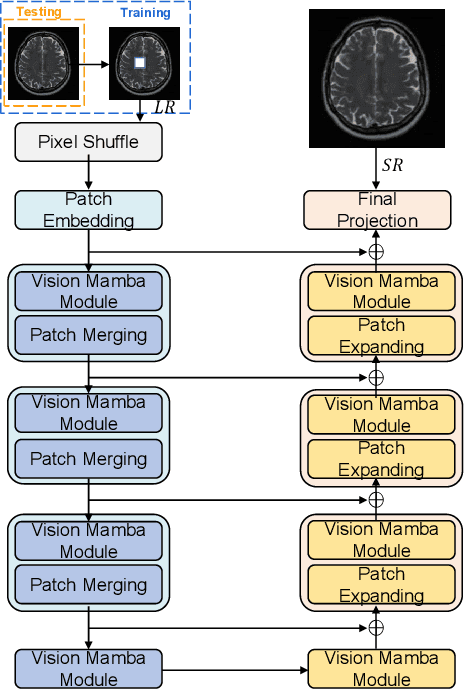
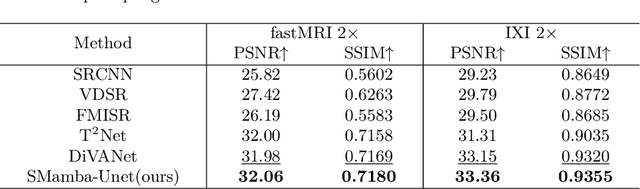
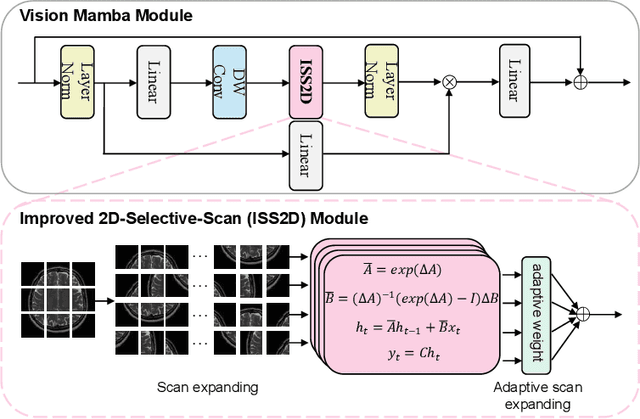
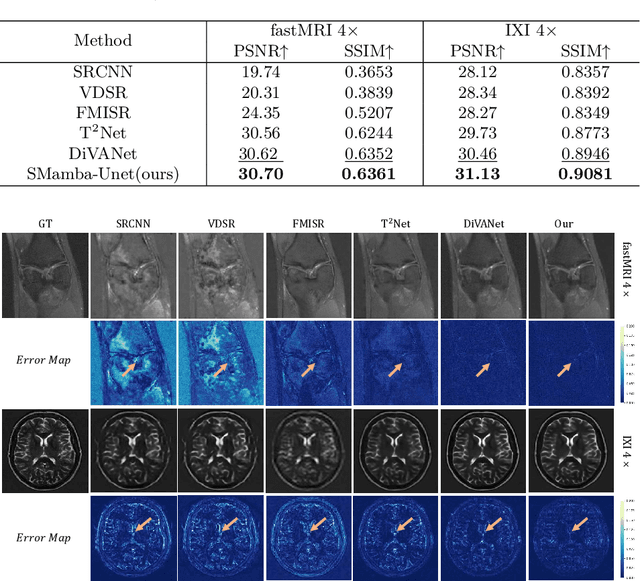
In this paper, we propose a self-prior guided Mamba-UNet network (SMamba-UNet) for medical image super-resolution. Existing methods are primarily based on convolutional neural networks (CNNs) or Transformers. CNNs-based methods fail to capture long-range dependencies, while Transformer-based approaches face heavy calculation challenges due to their quadratic computational complexity. Recently, State Space Models (SSMs) especially Mamba have emerged, capable of modeling long-range dependencies with linear computational complexity. Inspired by Mamba, our approach aims to learn the self-prior multi-scale contextual features under Mamba-UNet networks, which may help to super-resolve low-resolution medical images in an efficient way. Specifically, we obtain self-priors by perturbing the brightness inpainting of the input image during network training, which can learn detailed texture and brightness information that is beneficial for super-resolution. Furthermore, we combine Mamba with Unet network to mine global features at different levels. We also design an improved 2D-Selective-Scan (ISS2D) module to divide image features into different directional sequences to learn long-range dependencies in multiple directions, and adaptively fuse sequence information to enhance super-resolved feature representation. Both qualitative and quantitative experimental results demonstrate that our approach outperforms current state-of-the-art methods on two public medical datasets: the IXI and fastMRI.
PassionSR: Post-Training Quantization with Adaptive Scale in One-Step Diffusion based Image Super-Resolution
Nov 26, 2024Diffusion-based image super-resolution (SR) models have shown superior performance at the cost of multiple denoising steps. However, even though the denoising step has been reduced to one, they require high computational costs and storage requirements, making it difficult for deployment on hardware devices. To address these issues, we propose a novel post-training quantization approach with adaptive scale in one-step diffusion (OSD) image SR, PassionSR. First, we simplify OSD model to two core components, UNet and Variational Autoencoder (VAE) by removing the CLIPEncoder. Secondly, we propose Learnable Boundary Quantizer (LBQ) and Learnable Equivalent Transformation (LET) to optimize the quantization process and manipulate activation distributions for better quantization. Finally, we design a Distributed Quantization Calibration (DQC) strategy that stabilizes the training of quantized parameters for rapid convergence. Comprehensive experiments demonstrate that PassionSR with 8-bit and 6-bit obtains comparable visual results with full-precision model. Moreover, our PassionSR achieves significant advantages over recent leading low-bit quantization methods for image SR. Our code will be at https://github.com/libozhu03/PassionSR.
RealOSR: Latent Unfolding Boosting Diffusion-based Real-world Omnidirectional Image Super-Resolution
Dec 11, 2024



Omnidirectional image super-resolution (ODISR) aims to upscale low-resolution (LR) omnidirectional images (ODIs) to high-resolution (HR), addressing the growing demand for detailed visual content across a $180^{\circ}\times360^{\circ}$ viewport. Existing methods are limited by simple degradation assumptions (e.g., bicubic downsampling), which fail to capture the complex, unknown real-world degradation processes. Recent diffusion-based approaches suffer from slow inference due to their hundreds of sampling steps and frequent pixel-latent space conversions. To tackle these challenges, in this paper, we propose RealOSR, a novel diffusion-based approach for real-world ODISR (Real-ODISR) with single-step diffusion denoising. To sufficiently exploit the input information, RealOSR introduces a lightweight domain alignment module, which facilitates the efficient injection of LR ODI into the single-step latent denoising. Additionally, to better utilize the rich semantic and multi-scale feature modeling ability of denoising UNet, we develop a latent unfolding module that simulates the gradient descent process directly in latent space. Experimental results demonstrate that RealOSR outperforms previous methods in both ODI recovery quality and efficiency. Compared to the recent state-of-the-art diffusion-based ODISR method, OmniSSR, RealOSR achieves significant improvements in visual quality and over \textbf{200$\times$} inference acceleration. Our code and models will be released.
Adversarial Diffusion Compression for Real-World Image Super-Resolution
Nov 20, 2024



Real-world image super-resolution (Real-ISR) aims to reconstruct high-resolution images from low-resolution inputs degraded by complex, unknown processes. While many Stable Diffusion (SD)-based Real-ISR methods have achieved remarkable success, their slow, multi-step inference hinders practical deployment. Recent SD-based one-step networks like OSEDiff and S3Diff alleviate this issue but still incur high computational costs due to their reliance on large pretrained SD models. This paper proposes a novel Real-ISR method, AdcSR, by distilling the one-step diffusion network OSEDiff into a streamlined diffusion-GAN model under our Adversarial Diffusion Compression (ADC) framework. We meticulously examine the modules of OSEDiff, categorizing them into two types: (1) Removable (VAE encoder, prompt extractor, text encoder, etc.) and (2) Prunable (denoising UNet and VAE decoder). Since direct removal and pruning can degrade the model's generation capability, we pretrain our pruned VAE decoder to restore its ability to decode images and employ adversarial distillation to compensate for performance loss. This ADC-based diffusion-GAN hybrid design effectively reduces complexity by 73% in inference time, 78% in computation, and 74% in parameters, while preserving the model's generation capability. Experiments manifest that our proposed AdcSR achieves competitive recovery quality on both synthetic and real-world datasets, offering up to 9.3$\times$ speedup over previous one-step diffusion-based methods. Code and models will be made available.